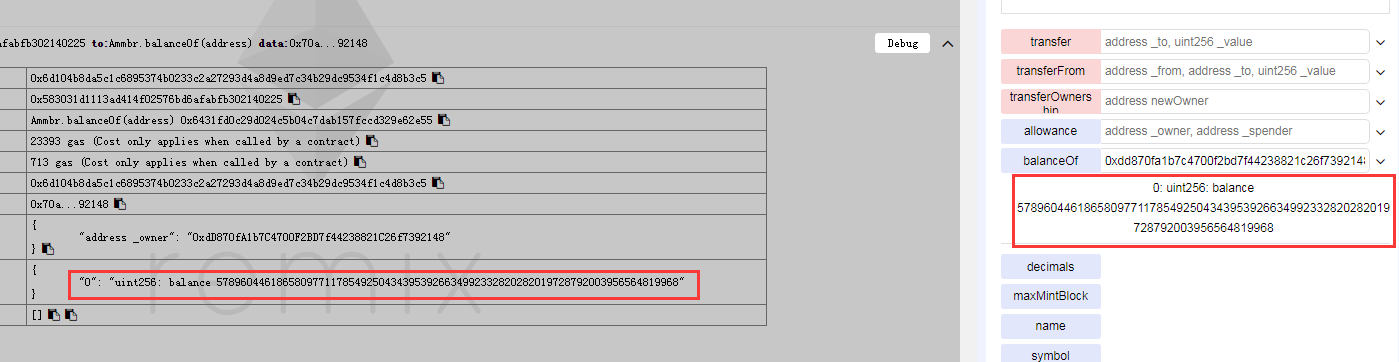
/** * @dev Function is used to perform a multi-transfer operation. This could play a significant role in the Ammbr Mesh Routing protocol. * * Mechanics: * Sends tokens from Sender to destinations[0..n] the amount tokens[0..n]. Both arrays * must have the same size, and must have a greater-than-zero length. Max array size is 127. * * IMPORTANT: ANTIPATTERN * This function performs a loop over arrays. Unless executed in a controlled environment, * it has the potential of failing due to gas running out. This is not dangerous, yet care * must be taken to prevent quality being affected. * * @param destinations An array of destinations we would be sending tokens to * @param tokens An array of tokens, sent to destinations (index is used for destination->token match) */ functionmultiTransfer(address[] destinations, uint[] tokens) publicreturns (bool success){ // Two variables must match in length, and must contain elements // Plus, a maximum of 127 transfers are supported assert(destinations.length > 0); assert(destinations.length < 128); assert(destinations.length == tokens.length); // Check total requested balance uint8 i = 0; uint totalTokensToTransfer = 0; for (i = 0; i < destinations.length; i++){ assert(tokens[i] > 0); totalTokensToTransfer += tokens[i]; } // Do we have enough tokens in hand? assert (balances[msg.sender] > totalTokensToTransfer); // We have enough tokens, execute the transfer balances[msg.sender] = balances[msg.sender].sub(totalTokensToTransfer); for (i = 0; i < destinations.length; i++){ // Add the token to the intended destination balances[destinations[i]] = balances[destinations[i]].add(tokens[i]); // Call the event... emit Transfer(msg.sender, destinations[i], tokens[i]); } returntrue; }
批量转账函数
address[] destinations 地址列表 uint[] tokens 转账数量
在函数开始对地址长度之类的校验,对我们没什么用。
1 2 3 4
for (i = 0; i < destinations.length; i++){ assert(tokens[i] > 0); totalTokensToTransfer += tokens[i]; }
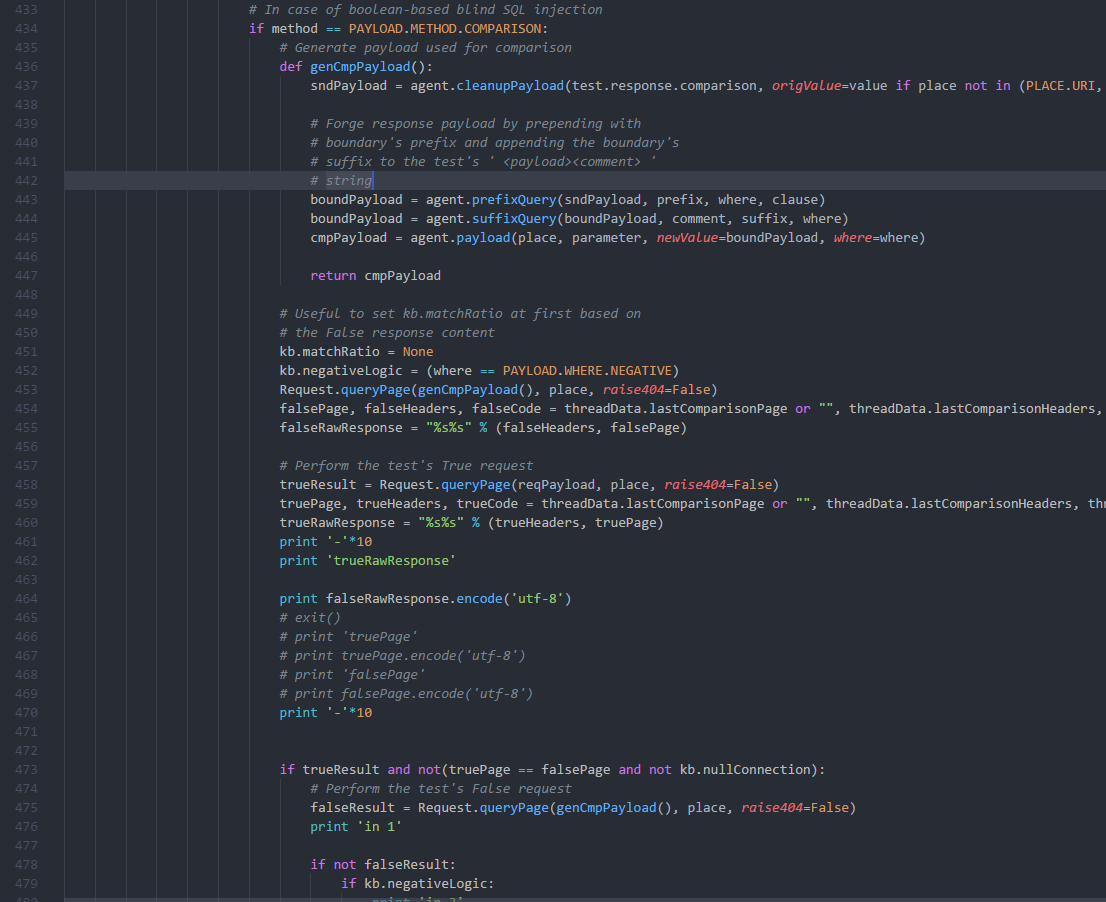
if place in (PLACE.POST, PLACE.GET): for regex in (r"\A((?:<[^>]+>)+\w+)((?:<[^>]+>)+)\Z", r"\A([^\w]+.*\w+)([^\w]+)\Z"): match = re.search(regex, testableParameters[parameter]) if match: try: candidates = OrderedDict() defwalk(head, current=None): if current isNone: current = head if isListLike(current): for _ in current: walk(head, _) elif isinstance(current, dict): for key in current.keys(): value = current[key] if isinstance(value, (list, tuple, set, dict)): if value: walk(head, value) elif isinstance(value, (bool, int, float, basestring)): original = current[key] if isinstance(value, bool): current[key] = "%s%s" % (str(value).lower(), BOUNDED_INJECTION_MARKER) else: current[key] = "%s%s" % (value, BOUNDED_INJECTION_MARKER) candidates["%s (%s)" % (parameter, key)] = re.sub("(%s\s*=\s*)%s" % (re.escape(parameter), re.escape(testableParameters[parameter])), r"\g<1>%s" % json.dumps(deserialized), parameters) current[key] = original deserialized = json.loads(testableParameters[parameter]) walk(deserialized)
def_comparison(page, headers, code, getRatioValue, pageLength): threadData = getCurrentThreadData() if kb.testMode: threadData.lastComparisonHeaders = listToStrValue([_ for _ in headers.headers ifnot _.startswith("%s:" % URI_HTTP_HEADER)]) if headers else"" threadData.lastComparisonPage = page threadData.lastComparisonCode = code print'kb.testMode'
if page isNoneand pageLength isNone: returnNone print"2-->" print conf.string if any((conf.string, conf.notString, conf.regexp)): rawResponse = "%s%s" % (listToStrValue([_ for _ in headers.headers ifnot _.startswith("%s:" % URI_HTTP_HEADER)]) if headers else"", page) # String to match in page when the query is True and/or valid if conf.string: print conf.string return conf.string in rawResponse
# String to match in page when the query is False and/or invalid if conf.notString: return conf.notString notin rawResponse
# Regular expression to match in page when the query is True and/or valid if conf.regexp: return re.search(conf.regexp, rawResponse, re.I | re.M) isnotNone print'can you here'
# In case of error-based SQL injection elif method == PAYLOAD.METHOD.GREP: # Perform the test's request and grep the response # body for the test's <grep> regular expression try: page, headers = Request.queryPage(reqPayload, place, content=True, raise404=False) output = extractRegexResult(check, page, re.DOTALL | re.IGNORECASE) \ or extractRegexResult(check, listToStrValue( \ [headers[key] for key in headers.keys() if key.lower() != URI_HTTP_HEADER.lower()] \ if headers elseNone), re.DOTALL | re.IGNORECASE) \ or extractRegexResult(check, threadData.lastRedirectMsg[1] \ if threadData.lastRedirectMsg and threadData.lastRedirectMsg[0] == \ threadData.lastRequestUID elseNone, re.DOTALL | re.IGNORECASE)
if output: result = output == "1"
if result: infoMsg = "%s parameter '%s' is '%s' injectable " % (paramType, parameter, title) logger.info(infoMsg)
# In case of time-based blind or stacked queries # SQL injections elif method == PAYLOAD.METHOD.TIME: # Perform the test's request trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False) trueCode = threadData.lastCode
if trueResult: # Extra validation step (e.g. to check for DROP protection mechanisms) if SLEEP_TIME_MARKER in reqPayload: falseResult = Request.queryPage(reqPayload.replace(SLEEP_TIME_MARKER, "0"), place, timeBasedCompare=True, raise404=False) if falseResult: continue
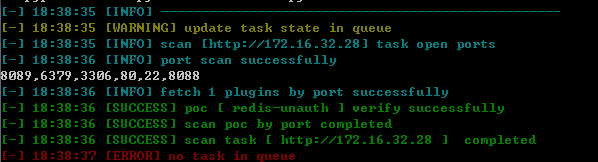
* A plugins weB vulnerability Scanner. * Author : bey0nd [at] (http://www.itwzw.cn)
optional arguments: -h, --help show this help message and exit -u [HOST [HOST2 HOST3 ...] [HOST [HOST2 HOST3 ...] ...]] Scan several url from command line -f TargetFile Load new line delimited targets from TargetFile -p , --plugins Load plugins from TargetDirectory -cookie name=value HTTP cookies for Target
[-] 11:39:05 [INFO] check target [172.16.32.97] with plugins [redis-remote] [-] 11:39:05 [INFO] check target [172.16.32.97] with plugins [redis-unauth] [-] 11:39:05 [INFO] all target[s] is done , check result with output